Authors: Baichuan Jiang, Keshuai Xu, Dr. Ernest Graham, Dr. Russell H. Taylor, Dr. Mathias Unberath, Dr. Emad M. Boctor
Abstract:
Fetal biometry and anatomical survey are usually done by sonographers manually searching for a set of standard plane (SP) images using 2D ultrasound probe. This task is nontrivial because it requires high skills of hand-eye coordination for maneuvering the 2D ultrasound probe, which could be even more challenging when fetus is at unfavorable pose or mother exhibits a high body mass index (BMI). Therefore, we envisioned a portable 3D ultrasound device that would help capture standard plane images from 3D volumes at home in challenging cases to avoid repetitive hospital visits. In this paper, we describe our first steps toward automatic extraction of SP images from volumetric data.
Key words: Deep reinforcement learning, 3D ultrasound, Standard plane extraction.
Methodology and results
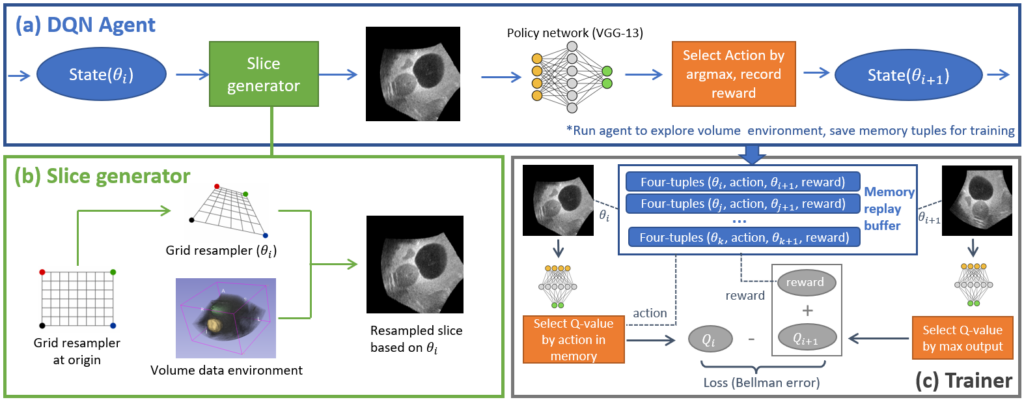
We use a deep Q-network agent to model the process of iteratively searching for the target 2D view from a 3D volume. Given a random initial pose of the starting plane, the network is able to produce a 6-Degree-of-Freedom (DOF) discrete action
that moves the plane one step closer to the target.
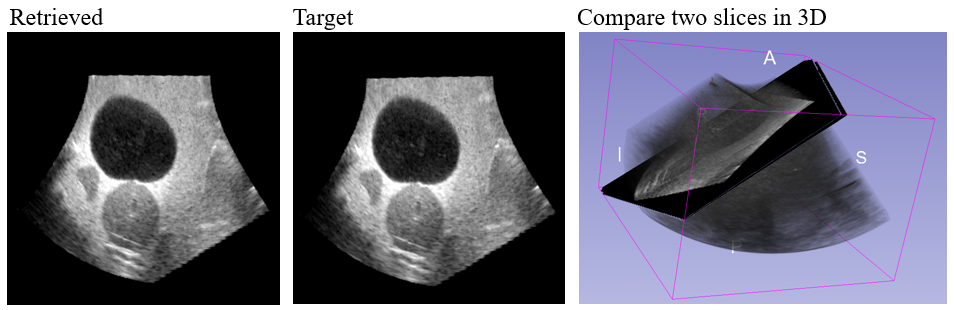
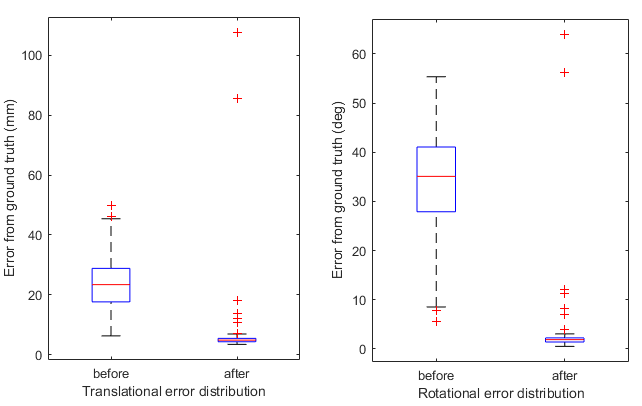
Our phantom experiment shows that the trained agent is able to correctly extract the target view image from a newly acquired 16cm depth large 3D ultrasound test volume within 150 action steps and achieve an average error of 5.51 mm and 2.26 deg, from different starting pose initializations.
Publication:
[1] Standard Plane Extraction From 3D Ultrasound With 6-DOF Deep Reinforcement Learning Agent (IUS 2020) (DOI link to be updated)